專題內容
01.專題環境介紹
教授並沒有規定專題製作環境,環境讓我們自行決定。不管是在圖書館、咖啡廳、甚至家裡,只要能讓自己足夠專注且舒適,都能在自己所喜歡的環境製作專題。
在製作過程中遇到問題時,也能透過與教授約好時間進行meeting,讓教授能夠給予遇到問題時的我們幫助。在製作專題期間,教授也會藉由每兩個禮拜一次的會議,以製作簡報的方式在會議中向大家和教授報告進度。
02.專題詳述
1.專題動機
面臨大量的學習資料和繁重的學習任務,如何有效率組織和理解這些資料成為一大挑戰。大型語言模型的出現,大幅度提升了學習的效率。例如,傳統上,我們需要花費大量時間自行閱讀整本課本並整理出重點,同時老師們也要在課本內容中設計出題目。然而,現在透過大型語言模型的幫助,我們可以在短短一分鐘內獲取整本書的重點摘要和設計出題目,極大地提升了學習和教學的效率。
現今,在企業中大型語言模型也常被運用,當成提升工作效率的工具。但不同於學生可以從網路中搜尋到書本相關知識,企業內部資料是無法被放在公開網路上的,且想利用公開網站尋求大型語言模型的幫助對企業來說也有安全疑慮。因此企業內部中龐大的資訊及資料庫(客戶資料、公司內部管理條例等等),要如何安全且正確的利用大型語言模型當作工具呢?
因此我所選擇的主題是利用大型語言模型(OpenAI的ChatGPT),開發一個結合檢索增強生成( Retrieval-Augmented Generation, RAG)和維基百科為知識庫的本地AI助理,效仿小型企業中利用大型語言模型的流程。
2. 大型語言模型(Large Language Model, LLM)
大型語言模型(Large Language Model, LLM),以ChatGPT-4為例,訓練內容涵蓋了來自各種來源的數百億個單詞,這些資料包括書籍、文章、網站內容、學術論文等,並且經過數個月,花費數百萬美元的經費,才能訓練完成。
傳統的機器學習(Machine Learning)主要使用監督式學習(supervised learning),這需要訓練者提供標記好的“對”與“錯”的資料來進行學習。透過這種方式,模型可以學習並延伸到未提供準確答案的新圖像,找出其規律及判斷方法。相比之下,LLM的學習則是非監督式(unsupervised learning)的,這意味著並未給定正確答案,而是讓LLM自行從大量資料中找到規律。
另外,LLM的訓練過程還包括自監督學習(self-supervised learning),這是一種介於監督式和非監督式之間的方法。自監督學習利用了部分已知的數據特徵來訓練模型,例如給定一段文本的前部分,模型需要預測後半部分。這種方式使得LLM能夠在沒有明確標記的情況下有效學習語言規律。
LLM的訓練內容主要集中在語義理解和生成上。訓練過程中,學習了大量的文本數據,涵蓋各種語言模式和結構,從而能夠理解和生成自然語言。
包括以下四項:
-
語法和句法結構:了解如何構造語法正確和語義清晰的句子。
-
語義理解:理解文本的意圖、上下文和意義,以便能夠在不同情境下給出合適的回應。
-
對話管理:能夠進行連貫的對話,記住上下文,並根據對話進行邏輯推理。
-
知識積累:包括各種領域的知識,如科學、歷史、技術等,以便能夠回答廣泛的問題。
早期的資料搜尋中,當你搜尋“喜歡”,所找出來的資料是包含一模一樣的詞語“喜歡”的結果。然而,LLM所學習的是語義,因此能夠分清楚“喜歡”、“蠻不錯”、“非常欣賞”等等有可能相同的意思,因而找到更多相關內容給你。LLM的做法是通過將文字轉成tokens(一種切割文字的單位),並把tokens向量化。例如,我們會發現“公主”和“王子”、 ”princess”和”prince”的向量分別套入數學公式中,他們得出的答案向量類似。LLM就是利用文字轉成有意義的向量空間後,利用數字去區分哪需詞語之間有語義的相似,從而更準確地回答問題。
接著LLM會進行“猜字接龍”的方式訓練。例如,“我”後面有90%的機率接“好”,而“我好”後面有80%的機率接“想”,“我好想”後面又有多少機率接其他字。LLM透過吸收大量資料來學習這些機率與拼字,從而讓自己能夠生成流暢且無誤的自然語言。
因此在企業需要使用LLM時,由於成本和時間的考量,大部分企業不會自己進行LLM的訓練。相反的,他們會透過購買已經訓練好的LLM API,將其作為工具應用於企業中。
現今的LLM仍然存在許多問題,例如幻覺現象和因訓練數據中的偏見而反映出的偏頗訊息。所謂的幻覺,是指LLM在無法從網路上找到相關資料時,憑空捏造出不屬實的回答。例如,當你詢問LLM明年某一天全球所有城市的天氣狀況時,因為這需要即時的天氣數據,而LLM無法訪問這些數據,他可能會生成一個看似合理但實際不準確的回答,假裝他已知道這些訊息。
因此LLM是一個非常智能且強大的工具,但在使用時我們仍需對於其回答保持敏感和判別的能力,以免誤用其提供的資訊。
3.檢索增強生成(Retrieval-Augmented-Generation)
RAG是一種結合檢索和生成技術的自然語言處理方式,旨在提升模型回答的準確性和相關性。
RAG方法包括兩個主要步驟:
-
檢索(Retrieval):
利用檢索模型從大量文本數據庫中找出與問題最相關的文黨或片段,通常基於已經訓練好的語言模型來表示和匹配文本。
-
生成(Generation):
同樣基於已經訓練好的語言模型,在獲取相關文黨或片段後,基於這些文黨生成回答。語言模型能夠將檢索到的訓息與問題結合,生成連貫且有意義的回答。
通過檢索相關訊息,RAG可以顯著提高回答的準確性,避免生成模型單獨工作時可能出現的幻覺問題,檢索步驟提供了生成回答的依據,使回答更具可解釋性。RAG可以靈活應用於多種任務,包括問答系統、對話系統和訊息檢索等。
利用RAG技術處理和檢索公司內部敏感訊息,可以提高問答系統的準確性和相關性,為使用者提供更有價值的答案,同時保證訊息安全與準確性。
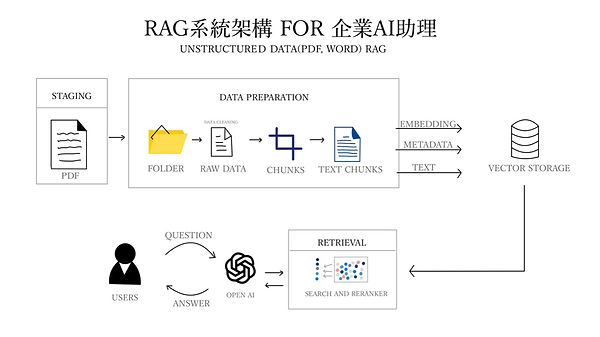
4.RAG系統架構 FOR 企業AI助理
RAG的系統架構如上圖所示,大致可分為上下兩個部分:
資料準備過程(Data Preparation)
-
放置文件:將未處理的PDF或WORD文件放置在資料夾中,整理成原始資料(Raw Data)。
-
拆分資料:將原始資料進一步拆分成較小的資料塊(Chunks)。
-
文本轉換:將資料塊轉為文本資料塊(Text Chunks),這些文本資料塊是經過處理後的可讀文本單位。
-
向量化和元數據生成:將文本資料塊轉為向量(Embedding),並同時生成相關的元數據(Metadata)。LLM進行資料向量化的速度非常快,根據具體的硬件配置和模型性能,平均處理一萬個Token(文本中的基本單位)只需要數秒鐘的時間。
-
儲存向量:將這些向量和元數據儲存到向量儲存庫(Vector Storage)中備用。
檢索和生成過程(Retrieval and Generation)
-
用戶查詢:用戶提出問題或查詢
-
問題處理:問題被送到LLM進行處理,轉為向量和文本塊。
-
檢索和排序:系統從向量儲存庫中檢索相關的向量和文本資料塊,並進行搜索和重新排序(Search and Reranker),以找到最相關的答案。
-
答案生成:檢索到的相關資料會與用戶的問題結合,利用LLM的語義知識生成最合適的答案,並回傳給用戶。
03.專題成果
資料存放
以元智大學為例,假設元智大學是間公司,我放入的為元智大學的一些條例、規則或是各系的必選修,共27個大小不一的PDF檔案,如下圖。
且各檔案的字數與Token數統計如下:
共計單詞量:51393 / Tokens數:268383
並讓程式進行embedding,且存入Vector Storage。
所花費的時間如下圖:
總計花費17073milliseconds = 17.073 seconds
實際操作
與使用者互動介面如下圖所示:
擁有維基百科的基本資訊:
雖問的問題與給定的資訊無關,但仍能透過維基百科的基本知識回答,如下圖示範:
對於有存在Vector storage的資料,AI助理除了給予基本語言模型語意理解和維基百科的資訊外,會顯示是否有找到資料內有相似的檔案存在,並回傳個數。
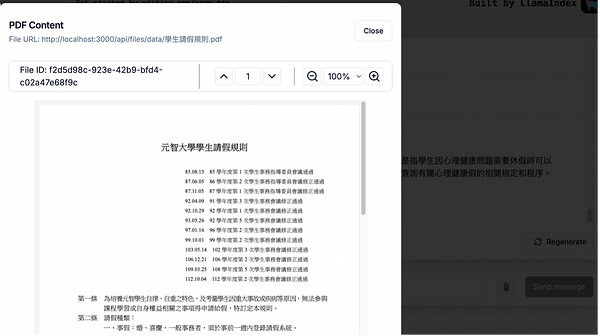
如下圖,有找到一個與問題:“元智大學有哪些請假類型”相關之檔案:
點選”sources”1,則可以看到他所找到的資料
如下圖所示,AI助理可以從27個PDF中找出一個檔案(元智大學學生請假規則),並透過大型語言模型,結合與檔案內的內容理解回答使用者問題
當詢問的問題並非給予的檔案內容,且無法從維基百科上面搜尋到的資訊,例如其他公司(學校)的內部文件(這裡以O O大學為例),雖然還是有找到與“請假類型”相關之source,但因並未是元智大學的,因此AI助理則會返回“無法得知”之回答,如下圖:
通過AI助理的幫助,當需查詢公司內部文件時,可以減省許多自己去爬文件資料的時間,且能快速並準確地找出所有與詢問之問題相關的檔案,確保檔案來源正當且正確。不僅提升公司內部效率,也能讓找尋資料變得更加方便。